 Poslední místa –
Poslední místa – Naučte se, jak v R snadno upravit strukturu vašich dat do standardizovaného formátu tidy data. Seznamte se se základními funkce balíčku tidyr pro pivotování, rozdělování a spojování sloupců, které vám usnadní další analýzu a vizualizaci dat.
V předchozích dílech série jsme se seznámili se základními pojmy a funkcemi jazyka R, představili jsme si ekosystém tidyverse a naučili se importovat data z různých zdrojů:
- Zpracování dat v R tidyverse – 1. díl: základní pojmy a funkce
- Zpracování dat v R tidyverse – 2. díl: import dat z Excelu, TIBCO Statistica a SPSS
- Zpracování dat v R tidyverse – 3. díl: import dat z aplikací SAS, MATLAB a Stata
Nyní se zaměříme na další klíčový krok v procesu zpracování dat – úpravu jejich struktury. Cílem tohoto kroku je transformovat surová data z výzkumu do uspořádané podoby (tzv. tidy dat). To je nezbytné pro zajištění kvality našich výstupů, ať už jde o statistickou analýzu, vizualizaci nebo modelování.
Tidy data – základ kvalitní statistické analýzy v jazyce R
Tidy data představují standardizovaný, přehledný způsob uspořádání dat. Řídí se třemi základními pravidly:
- každá proměnná (statistický znak) má svůj vlastní sloupec,
- každé pozorování (měření) má svůj vlastní řádek,
- každá hodnota má svou vlastní buňku.
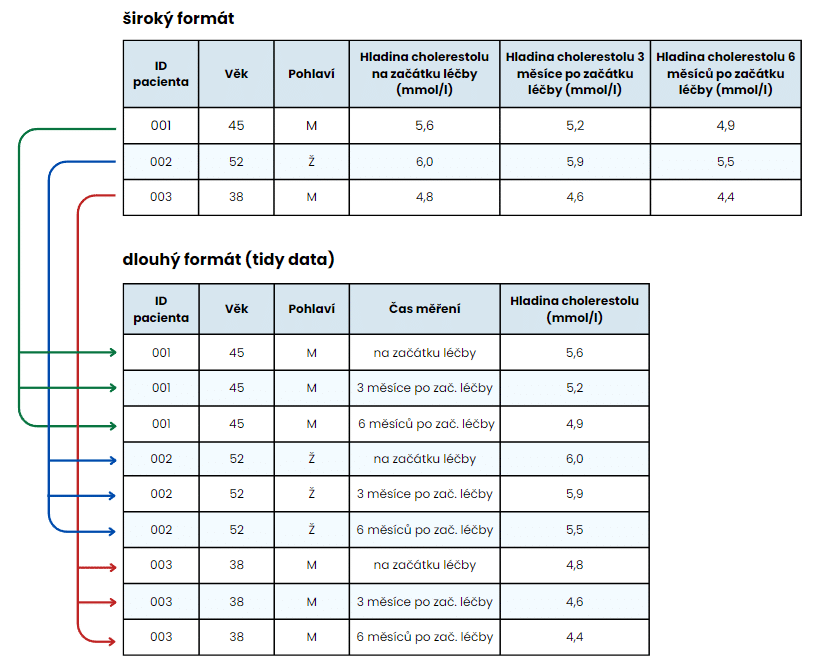
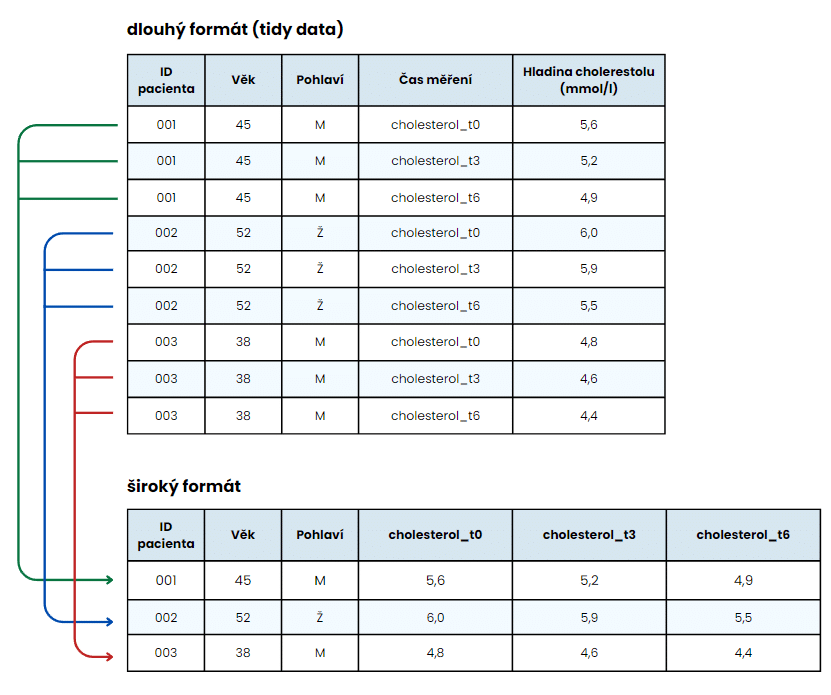
Příklad převodu klasické tabulky do tidy data formátu. Všimněte si, že v první tabulce jsou na jeden řádek tři pozorování (hladina cholesterolu před léčbou a hladina cholesterolu 3 měsíce, resp. 6 měsíců po léčbě), zatímco u druhé tabulky má každý řádek pouze jedno pozorování (buď hladina cholesterolu před léčbou, hladina cholesterolu 3 měsíce po léčbě nebo hladina cholesterolu 6 měsíců po léčbě).
Formát tidy dat je klíčový pro efektivní a intuitivní práci s daty, protože poskytuje konzistentní strukturu sloupců a řádků, která usnadňuje datovou manipulaci (balíček dplyr), analýzu a vizualizaci (balíček ggplot2).

Tidy data minimalizují riziko chyb při zpracování a vyhodnocování dat, umožňují lepší přenositelnost a znuvupoužitelnost kódu, což z nich činí základ úspěšné datové analýzy v R.Na úpravy dat do tidy formátu pomocí konkrétních funkcí z balíčku tidyr se podíváme níže. Předtím si ale ještě vysvětlíme, proč data ukládat do tzv. tibble struktury.
Co je tibble (a proč s ním pracovat)
Programovací jazyk R využívá různé datové struktury (objekty), mezi které patří vektory (vector), matice (matrix), seznamy (list) a datové rámce (data frame). Podrobně jsme se jim věnovali v prvním dílu této série. Pro práci s tidy daty je však klíčová struktura zvaná tibble.
Tibble představuje moderní alternativu k tradičním datovým rámcům v R. Jde o vylepšenou verzi datového rámce, která je součástí ekosystému tidyverse. Tibble zachovává všechny základní vlastnosti datového rámce, ale přidává několik užitečných vylepšení, např.:
- přehlednější výpis – tibble automaticky zobrazuje pouze prvních několik řádků a sloupců dat, což usnadňuje práci s velkými datovými sadami,
- zachování datových typů – automaticky nemění datové typy sloupců, což zabraňuje nechtěným konverzím (např. změna identifikačního čísla pacienta z textu – character – na číslo – numeric),
podpora nestandardních názvů sloupců – tibble umožňuje používat mezery a speciální znaky v názvech sloupců (pokud je do kódu vložíme v uvozovkách “” a takto s nimi pracujeme i v dalších funkcích).

Při zobrazení tibble struktur v okně Console získáte dodatečné informace, jako je typ dat v daném sloupci nebo rozměry tabulky.
Pro převod stávajících datových struktur (data frame, matrix, list a další) nejprve nainstalujte a načtěte soubor balíčků tidyverse:
# instalace tidyverse
install.packages("tidyverse")
# načtení tidyverse
library(tidyverse)Pro převod dat do tibble slouží funkce ‚as_tibble‘. Základní použití vypadá takto:
# převod data frame struktury "cholesterol" do tibble struktury "cholesterol_t"
cholesterol_t <- as_tibble(cholesterol)Mezi nejpoužívanější argumenty funkce ‚as_tibble‘ patří:
- ‚.name_repair‘ – určuje, jak opravit názvy sloupců (pokud se např. určitý název opakuje). Možné hodnoty jsou ‚minimal‘ (žádná oprava), ‚check_unique‘ (kontrola jedinečnosti pojmenování sloupců bez opravy – výchozí nastavení), ‚unique‘ (vytvoří jedinečná pojmenování sloupců přidáním čísel k duplicitním názvům), ‚universal‘ (vytvoří jedinečná pojmenování sloupců) nebo vlastní funkce.
- ‚rownames‘ – určuje, jak zacházet s názvy řádků. Základní možnosti jsou ‚NULL‘ (odstraní jména řádků – výchozí nastavení) nebo ‚NA‘ (zachová jména řádků).
# převod data frame struktury "cholesterol" do tibble struktury "cholesterol_t" s přejmenováním duplicitních názvů sloupců
cholesterol_t <- as_tibble(cholesterol, .name_repair = "unique")Pro vytvoření tibble struktury od základu slouží funkce ‚tibble‘. Každé proměnné je třeba přiřadit hodnoty. Pro přehlednost označujeme čas měření jako „cholesterol_tX“, kde X je počet měsíců po zahájení léčby:
# vytvoření základní tibble struktury
cholesterol_t <- tibble(
ID_pacienta = c("001", "002", "003"),
Věk = c(45, 52, 38),
Pohlaví = c("M", "Ž", "M"),
cholesterol_t0 = c(5.6, 6.0, 4.8),
cholesterol_t3 = c(5.2, 5.9, 4.6),
cholesterol_t6 = c(4.9, 5.5, 4.4))Intuitivnější vytvoření tibble struktury (podle výsledného rozmístění buněk v tabulce) poskytuje funkce ‚tribble‘. Název každé funkce se uvozuje tildou (~):
# vytvoření tibble struktury pomocí funkce ‚tribble‘
cholesterol_t <- tribble(
~ID_pacienta, ~Věk, ~Pohlaví, ~cholesterol_t0, ~cholesterol_t3, ~cholesterol_t6,
"001", 45, "M", 5.6, 5.2, 4.9,
"002", 52, "Ž", 6.0, 5.9, 5.5,
"003", 38, "M", 4.8, 4.6, 4.4)
Výsledná tibble tabulka, se kterou budeme pracovat v dalších příkladech
V praxi vzniká tibble struktura nejčastěji importem souborů, ruční tvorba pomocí kódu je výjimečnou záležitostí.
Pro ověření, zda má datová struktura tibble charakter, slouží funkce ‚is_tibble(nazev-struktury)‘. Využijete ji např. po importu dat z Excelu, SPSS, TIBCO Statistica a dalších aplikací pro datovou analýzu.
Pivotování dat (transformace na tidy data a zpět)
Pivotování dat je klíčovou technikou pro transformaci datových struktur v rámci tidyverse ekosystému. Tato operace umožňuje efektivně měnit formát dat mezi širokou a dlouhou (tidy) formou (viz výše).
Při pivotování je důležité pochopit strukturu vašich dat a identifikovat, které části představují proměnné a které hodnoty. Toto rozhodnutí závisí na kontextu dat a cíli vaší analýzy.
U naší ukázkové tabulky před úpravou máme tyto proměnné:
- ID pacienta – nominální proměnná; každý pacient má unikátní kód, který neslouží pro měření, ale pro identifikaci jednotlivých pacientů,
- věk – spojitá proměnná; věk pacientů ale uvádíme v celých číslech (v letech),
- biologické pohlaví – nominální binární proměnná; nabývá dvou hodnot.
Všimněte si, že pojmenování sloupců s hladinou cholesterolu ve skutečnosti nejsou proměnné, ale hodnoty proměnné. V tomto případě jde o diskrétní proměnnou „čas měření“, jejíž hodnoty nabývají určitých čísel (zde měsíců od začátku léčby, kdy jsme změřili hladinu cholesterolu v krvi pacienta):
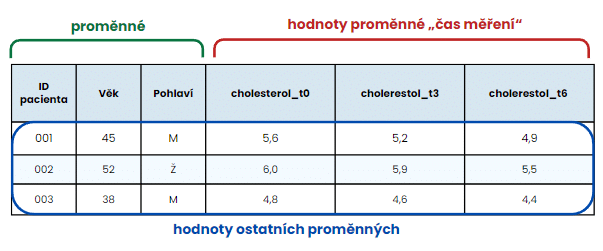
Pro zachování pravidel tidy dat (tedy: každá proměnná má svůj vlastní sloupec, každé měření má svůj vlastní řádek a každá hodnota má svou vlastní buňku) proto namísto několika sloupců pro měření cholesterolu v různých časových bodech vytvoříme jeden nový sloupec s proměnnou „čas měření“ a druhý pro hodnoty cholesterolu.
Výsledná tabulka by měla vypadat takto:
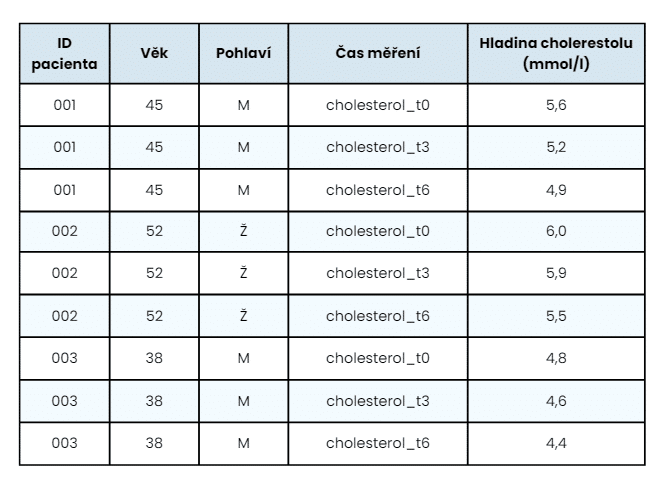
Z tabulky je patrné, že každé pozorování (měření) má nyní svůj vlastní řádek.
Pro transformaci dat do „dlouhého“ (tidy) formátu slouží funkce ‚pivot_longer‘ z balíčku tidyr (je součástí ekosystému tidyverse):
# instalace a načtení celého tidyverse
install.packages("tidyverse")
library(tidyverse)
# instalace a načtení balíčku tidyr
install.packages("tidyr")
library(tidyr)Pro úpravu tabulky do tidy formátu (který pojmenujeme „cholesterol_t_longer“) využijete ve funkci ‚pivot_longer‘ tyto argumenty:
- název upravované datové sady – vkládá se pouze jako název sady, v našem případě tedy „cholesterol_t“,
- ‚cols‘ – názvy sloupců, které budeme upravovat (v tomto případě sloupce „cholesterol_t0“, „cholesterol_t3“ a „cholesterol_t6“),
- ‚names_to‘ – název nového sloupce (nové proměnné), který bude obsahovat názvy původních sloupců; nový sloupec tedy pojmenujeme „čas měření“, hodnoty ve sloupci budou nyní „cholesterol_t0“, „cholesterol_t3“ a „cholesterol_t6“,
- ‚values_to‘ – název nového sloupce (nové proměnné), který bude obsahovat hodnoty pivotovaných sloupců (tedy hodnoty z původních sloupců „cholesterol_t0“, „cholesterol_t3“ a „cholesterol_t6“); v našem případě nový sloupce pojmenujeme „hodnota cholesterolu (mmol/l)“, jeho hodnoty budou naměřené údaje cholesterolu.
# úprava tibble struktury do dlouhého (tidy) formátu
cholesterol_t_longer <- pivot_longer(cholesterol_t,
cols = c("cholesterol_t0", "cholesterol_t3", "cholesterol_t6"),
names_to = "Čas měření",
values_to = "Cholesterol (mmol/l)")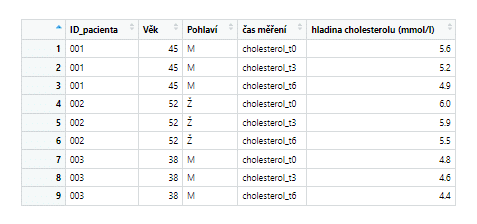
Tibble tabulka upravená do dlouhého (tidy) formátu
V praxi se můžeme setkat s tím, že názvy sloupců, které chceme pivotovat, se drží určitého vzoru nebo struktury. Mohou např. začínat stejnou předponou nebo obsahovat různé části oddělené podtržítkem či jinými znaky, jako jsou časové body, podmínky experimentu nebo kategorie.
Vypisování názvů více sloupců je nepraktické a zabere spoustu času. K argumentu ‚cols‘ proto můžete přidat doplňující hodnoty (funkce), které výběr sloupců výrazně zjednoduší:
- ‚cols = starts_with(“zacatek_nazvu_sloupce”)‘ – vybere všechny sloupce, které začínají určitým názvem (v našem případě bychom pro sloupce „cholesterol_t0“, „cholesterol_t3“ a „cholesterol_t6“ použili název „cholesterol_t“),
- ‚cols = ends_with(“konec_nazvu_sloupce”)‘ – vybírá sloupce, které končí na daný text, například pro sloupce končící na „_3“ (jako v experimentech s časovými body),
- ‚cols = contains(“text_uvnitr”)‘ – vybere sloupce, které obsahují určitý textový řetězec bez ohledu na jeho umístění.
Názvy pivotovaných sloupců lze během jejich transformace na hodnoty upravit. K tomu slouží argument ‚names_prefix‘, který z názvů pivotovaných sloupců odstraní předponu (např. „cholesterol_“):
# úprava tibble struktury do dlouhého (tidy) formátu a odstranění předpony „cholesterol_“
cholesterol_t_longer <- pivot_longer(cholesterol_t,
cols = starts_with("cholesterol",
names_prefix = "cholesterol_",
names_to = "čas měření",
values_to = "hladina cholesterolu (mmol/l)")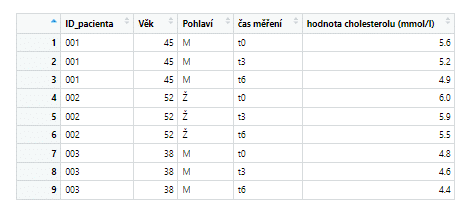
Výsledná tabulka
Pro úpravu dat z dlouhého (tidy) formátu do širokého (které obsahuje v jednom řádku více pozorování) existuje funkce ‚pivot_wider‘. Široký formát je přehlednější a snáze pochopitelný, hodí se např. pro prezentaci výsledků ve vědeckých publikacích.
Mezi hlavní argumenty patří:
- název upravované datové sady – vkládá se pouze jako název sady, v našem případě tedy „cholesterol_t_longer“,
- ‚names_from‘ – určuje sloupec (v našem případě „čas měření“), jehož hodnoty se stanou názvy nových sloupců ve výsledné široké tabulce,
- ‚values_from‘ – určuje sloupec, jehož hodnoty se použijí jako obsah nově vytvořených sloupců (v našem případě jde o sloupec „hladina cholesterolu (mmol/l)“).
# úprava tibble struktury do širokého formátu
cholesterol_t <- pivot_wider(cholesterol_t_longer,
names_from = ("čas měření"),
values_from = ("hladina cholesterolu (mmol/l)"))Oddělování a spojování sloupců
Při práci s daty často potřebujeme rozdělit jeden sloupec na více sloupců nebo naopak spojit několik sloupců do jednoho. Pro tyto účely nabízí balíček tidyr funkce ‚separate‘ a ‚unite‘. Při jejich demonstraci použijeme následující tabulku:
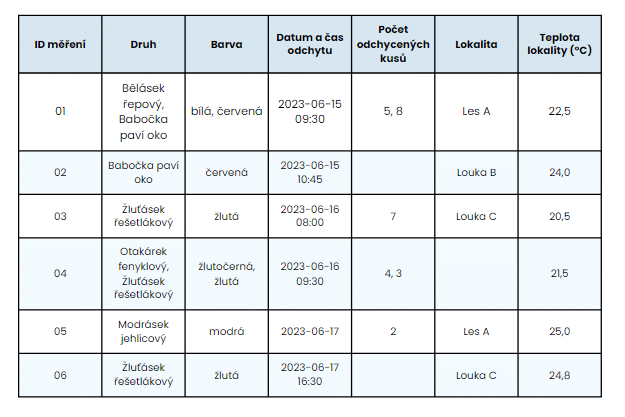
Funkce ‚separate‘, resp. nověji podporovaná ‚separate_wider_delim‘ umožňuje rozdělit jeden sloupec horizontálně na více sloupců podle určitého oddělovače nebo pozice znaků. Je užitečná, pokud máme např. v jednom sloupci více informací, které chceme analyzovat samostatně.
Při pohledu na tabulku výše můžeme např. rozdělit sloupec „datum a čas odchytu“ na „datum odchytu“ a „čas odchytu“.
Hlavní argumenty funkce ‚separate_wider_delim‘ jsou:
- název upravované datové sady – vkládá se pouze jako název sady, v našem případě „motyli“,
- ‚col‘ – specifikuje sloupec, který chceme rozdělit („datum a čas odchytu“),
- ‚names‘ – určuje názvy nových sloupců, které vzniknou rozdělením („datum odchytu“ a „čas odchytu“),
- ‚delim‘ – specifikuje oddělovač; pokud jde o určitý znak, např. mezeru, stačí jej specifikovat jako ” ” (pokud by šlo třeba o lomítko, specifikujeme jej jako “/”); můžete také specifikovat pozici oddělovače číslem – pokud chcete např. rozdělit hodnoty za 2. znakem, použijete argument ve tvaru ‚sep = 2‘,
- ‚too_few‘ – určuje, jak se má funkce zachovat, pokud v některém řádku chybí data; může nabývat hodnot ‚align_start‘ (doplní namísto chybějících hodnot na konec NA), ‚align_end‘ (doplní namísto chybějících hodnot na začátek NA) nebo ‚error‘ (pokud v některém řádku chybí data, vyvolá chybu).
# rozdělení sloupce „datum a čas odchytu“ na „datum odchytu“ a „čas odchytu“
motyli <- separate_wider_delim (motyli,
col = "Datum a čas odchytu",
names = c("Datum odchytu", "Čas odchytu"),
delim = " ",
too_few = "align_start")
Výchozí tabulka po použití funkce ‚separate_wider_delim‘
Funkci ‚separate_longer_delim‘ využijete k rozdělení jednoho sloupce na více řádků podle určitého oddělovače. Je užitečná v situacích, kdy máme v jednom sloupci uloženy různé hodnoty a potřebujeme každou z nich převést na samostatný řádek pro další zpracování a analýzu. (Více hodnot v jedné buňce navíc porušuje filozofii tidy dat.)
V našem případě můžeme chtít oddělit druhy motýlů ve sloupci „druh“ (a dále jejich barvy a počty odchycených kusů).
Hlavní argumenty funkce „separate_longer_delim()“ jsou:
- název datové sady – vkládá se jako název tabulky, v našem případě „motyli“,
- ‚col‘ – specifikuje sloupec (sloupce), který chceme rozdělit (v naší tabulce „druh“, „barva“ a „počet odchycených kusů“ – pokud bychom vložili pouze „druh“, barvy a počty odchycených kusů se nerozdělí a do nových řádků se jejich hodnoty pouze zkopírují),
- ‚delim‘ – udává znak, podle kterého se má rozdělovat; např. čárku s mezerou specifikujeme jako “, “.
# rozdělení více hodnot ve sloupcích „druh“, „barva“ a „počet odchycených kusů“ do samostatných řádků
motyli <- separate_longer_delim (motyli,
col = c("Druh", "Barva", "Počet odchycených kusů"),
delim = ", ")
Výchozí tabulka po použití funkce ‚separate_longer_delim‘
Funkce ‚unite’ slouží ke spojení dvou nebo více sloupců do jednoho. Je užitečná, když potřebujeme kombinovat informace z více sloupců do jednoho, např. při vytváření unikátních identifikátorů nebo při slučování data a času do jednoho sloupce.
V našem příkladu spojíme sloupce „druh“ a „počet odchycených kusů“ do sloupce „druh / počet odchycených kusů“.
Hlavní argumenty funkce ‚unite’ jsou:
- název upravované datové sady – vkládá se pouze jako název sady, v našem případě „motyli“,
- ‚col‘ – specifikuje název nového sloupce, který vznikne spojením („druh / počet odchycených kusů“),
- názvy sloupců, které spojujeme, v našem případě ‚c(“druh”, “počet odchycených kusů”); pokud máte sloupce pojmenované podle určitého vzoru, můžete pro jejich spojení použít hodnoty jako ‚cols = starts_with(“zacatek_nazvu_sloupce”)‘, ‚cols = ends_with(“konec_nazvu_sloupce”)‘ nebo ‚cols = contains(“text_uvnitr”)‘,
- ‚sep‘ – specifikuje oddělovač, který se použije mezi spojenými hodnotami (v naší sadě ” / “,
- ‚na.rm‘ – udává, co se stane s chybějícími hodnotami ve spojovaných sloupcích; při hodnotě ‚TRUE‘ dojde k jejich odstranění.
# spojení sloupců „druh“ a „počet odchycených kusů“ do sloupce „druh / počet odchycených kusů“
motyli <- unite(motyli,
col = "Druh / počet odchycených kusů",
c("Druh", "Počet odchycených kusů"),
sep = " / ",
na.rm = TRUE)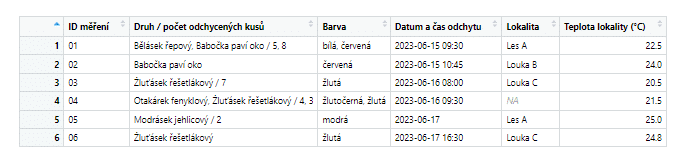
Výchozí tabulka po použití funkce ‚unite‘
Naučte se ovládat jazyk R pod dohledem zkušeného lektora
Kurz ovládání programovacího jazyka R pořádáme pravidelně v Praze i na dalších místech. Během 1denního kurzu se kromě základních funkcí naučíte do jazyka R data importovat, upravit je, analyzovat a nakonec vizualizovat.
Lektorem kurzu je Mgr. Patrik Galeta, PhD., odborný asistent katedry antropologie Západočeské univerzity v Plzni. Statistickým metodám se věnuje v rámci demografických studií, na ZČU vede také kurz zpracování dat.
Ze školení si navíc odnesete více než 40 skriptů, které můžete použít pro zpracování dat ze svého výzkumu.